Introduction to ArchaeoPhases
A. Philippe, M.-A. Vibet
2026-06-23
Source:vignettes/ArchaeoPhases.Rmd
ArchaeoPhases.RmdIntroduction
ArchaeoPhases provides a list of functions for the statistical analysis of archaeological dates and groups of dates. It is based on the post-processing of the Markov Chains whose stationary distribution is the posterior distribution of a series of dates. Such MCMC output can be simulated by different applications as for instance ChronoModel (Lanos et al. 2020), Oxcal (Bronk Ramsey 2009) or BCal (Buck et al. 1999). The only requirement is to have a CSV file containing a sample from the posterior distribution.
## Load packages
library(ArchaeoPhases)
library(coda) # MCMC diagnosticImport data
This vignette uses data available through the ArchaeoData package which is available in a separate repository. ArchaeoData provides MCMC outputs from ChronoModel, OxCal and BCal.
## Install data package
install.packages("ArchaeoData", repos = "https://archaeostat.r-universe.dev")Let’s use the data of Ksar Akil generated by ChronoModel (Bosch et al. 2015).
Two different files are generated by ChronoModel:
Chain_all_Events.csv that contains the MCMC samples of each
event created in the modeling, and Chain_all_Phases.csv
that contains all the MCMC samples of the minimum and the maximum of
each group of dates if at least one group is created.
## Construct the path to the data
chrono_path <- file.path("chronomodel", "ksarakil")
## Read events from ChronoModel
output_events <- system.file(chrono_path, "Chain_all_Events.csv", package = "ArchaeoData")
chrono_events <- read_chronomodel_events(output_events)
## Read phases from ChronoModel
output_phases <- system.file(chrono_path, "Chain_all_Phases.csv", package = "ArchaeoData")
chrono_phases <- read_chronomodel_phases(output_phases)See vignette("import") for more details on how to import
MCMC samples.
Convergence of MCMC chains
For more details on the diagnostic of Markov chain, see Robert and Casella (2010).
To assess the agreement between the posterior distributions and the numerical approximations, three Markov chains were run in parallel by ChronoModel. For each chain, 1 000 iterations were used during the Burn-in period, 20 batches of 500 iterations were used in the Adapt period, 100 000 iterations were drawn in the Acquire period by only 1 out of 10 were kept in order to break the correlation structure.
From the analysis of the history plot, all Markov chains reach their equilibrium before the Acquire period. The autocorrelations of the three Markov chains are not significant, meaning the rate of subsample (1 over 10) is enough.
Now, using the package ArchaeoPhases and the package coda, we can verify whether the MCMC samples are correctly generated by the software.
## Create an mcmc.list
coda_events <- as_coda(chrono_events, chains = 3)Indeed, the MCMC samples should have no autocorrelation and should have reached their equilibrium (that is the posterior density of the parameter under investigation).
coda::autocorr.plot(coda_events[[1]])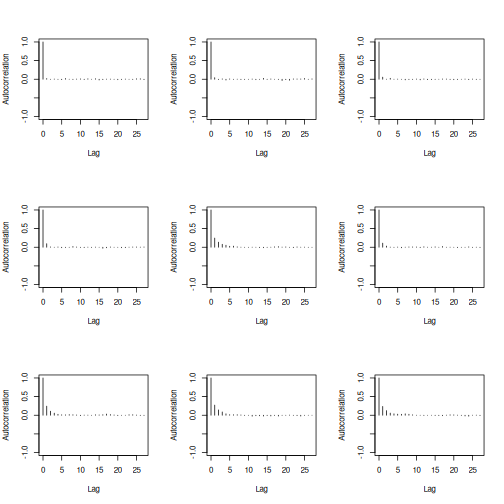
plot of chunk coda-autocor
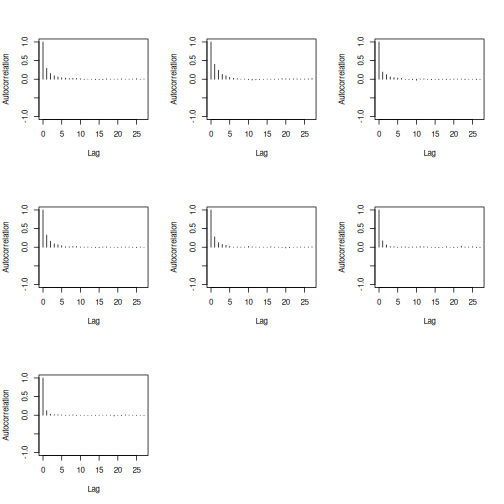
plot of chunk coda-autocor
The autocorrelation plots show that each of these three chains are not significant. That means that we actually generated a non correlated sample, which was the aim the MCMC process.
We can also check whether the chains reached equilibrium. For example, let’s consider the first date of the dataset.
plot(coda_events[, 1, ], trace = TRUE, density = FALSE)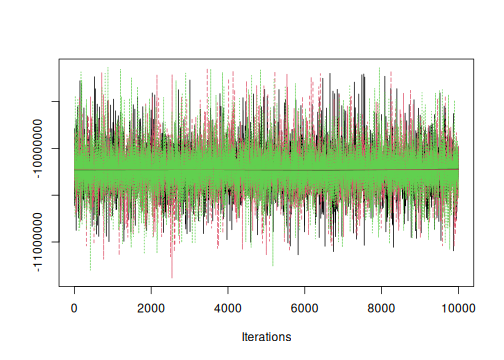
plot of chunk coda-plot
The plot shows that the three chains corresponding to the first date reached the same stationary process.
We can test the Gelman-Rubin criterion. The expected value to confirm that all of the Markov chains reached equilibrium is 1.
coda::gelman.diag(coda_events)
#> Potential scale reduction factors:
#>
#> Point est. Upper C.I.
#> [1,] 1 1
#> [2,] 1 1
#> [3,] 1 1
#> [4,] 1 1
#> [5,] 1 1
#> [6,] 1 1
#> [7,] 1 1
#> [8,] 1 1
#> [9,] 1 1
#> [10,] 1 1
#> [11,] 1 1
#> [12,] 1 1
#> [13,] 1 1
#> [14,] 1 1
#> [15,] 1 1
#> [16,] 1 1
#>
#> Multivariate psrf
#>
#> 1The Gelman-Rubin criterion confirms that all of the Markov chains reached equilibrium.
We can also test the Geweke criterion. The expected value to confirm that all of the Markov chains reached equilibrium is strickly less than 1.
coda::geweke.diag(coda_events[, 1, ], frac1 = 0.1, frac2 = 0.5)
#> [[1]]
#>
#> Fraction in 1st window = 0.1
#> Fraction in 2nd window = 0.5
#>
#> var1
#> 0.4978
#>
#>
#> [[2]]
#>
#> Fraction in 1st window = 0.1
#> Fraction in 2nd window = 0.5
#>
#> var1
#> 0.7736
#>
#>
#> [[3]]
#>
#> Fraction in 1st window = 0.1
#> Fraction in 2nd window = 0.5
#>
#> var1
#> 0.7666The Geweke criterion criterion confirms that all of the Markov chains reached equilibrium.
ChronoModel generated correct samples of the posterior distribution. Now gathering the three chains, a total of 30 000 iterations was collected in order to give estimations of the posterior distribution of each parameter.
Analysis of a series of dates
plot(chrono_events)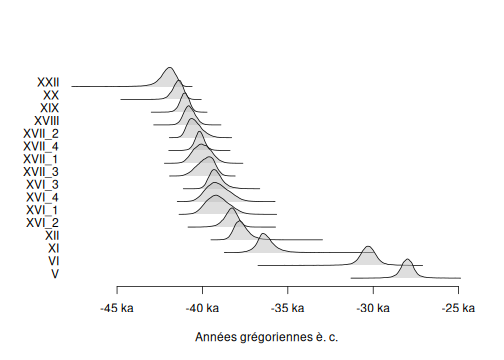
plot of chunk event-plot
Tempo Plot
The tempo plot has been introduced by Dye (2016). See Philippe and Vibet (2020) for more statistical details.
The tempo plot is one way to measure change over time: it estimates the cumulative occurrence of archaeological events in a Bayesian calibration. The tempo plot yields a graphic where the slope of the plot directly reflects the pace of change: a period of rapid change yields a steep slope and a period of slow change yields a gentle slope. When there is no change, the plot is horizontal. When change is instantaneous, the plot is vertical.
## Warning: this may take a few seconds
tp <- tempo(chrono_events, level = 0.95, count = FALSE)
plot(tp)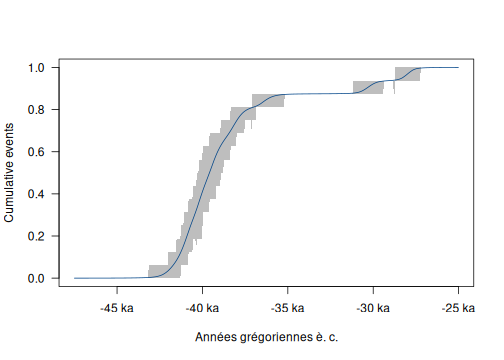
plot of chunk tempo-plot
From these graphs, we can see that the highest part of the sampled activity is dated between -45 000 to -35 000 but two dates are younger, at about -32 000 and -28 000.
Activity Plot
The activity plot displays the derivative of the Bayes estimate of the Tempo plot. It is an other way to see changes over time.
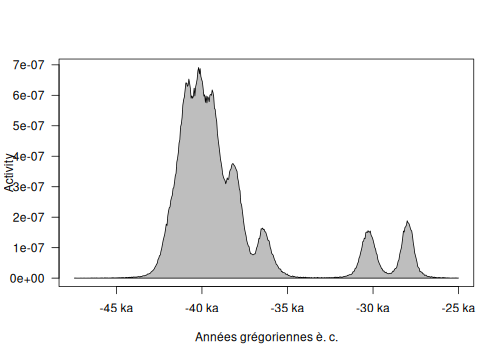
plot of chunk activity-plot
Occurrence Plot
The Occurrence plot calculates the calendar date corresponding to the smallest date such that the number of events observed before is equal to , for . The Occurrence plot draws the credible intervals or the highest posterior density (HPD) region of those dates associated to a desired level of confidence.
## Warning: this may take a few seconds
oc <- occurrence(chrono_events, level = 0.95)
plot(oc)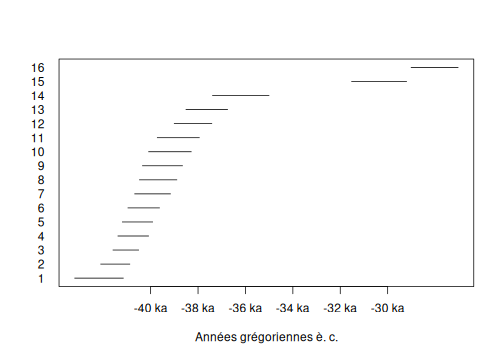
plot of chunk occurrence-plot
Analysis of groups of dates
Groups of dates
A group of dates (phase) is defined by the date of the minimum and the date of the maximum of the group. In this part, we will use the data containing these values for each group of dates.
## Build phases from events
p <- list(EPI = 1, UP = 2:4, Ahmarian = 5:15, IUP = 16)
chrono_groups <- phases(chrono_events, groups = p)
all(chrono_groups == chrono_phases)
#> [1] TRUEWe can estimate the time range of a group of dates as the shortest interval that contains all the dates of the group at a given confidence level (Philippe and Vibet 2020).
The following code gives the endpoints of the time range of all groups of dates of Ksar Akil data at a given confidence level.
bound <- boundaries(chrono_groups, level = 0.95)
as.data.frame(bound)
#> label start end duration
#> 1 EPI -28978.53 -26969.82 2008.712
#> 2 UP -38570.37 -29368.75 9201.622
#> 3 Ahmarian -42168.47 -37433.31 4735.159
#> 4 IUP -43240.37 -41161.00 2079.372The time range interval of the group of dates is a way to summarize the estimation of its minimum, the estimation of its maximum and their uncertainties at the same time.
plot(chrono_groups, level = 0.95)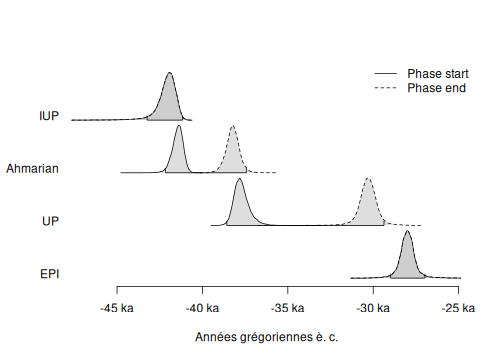
plot of chunk phases-plot
Succession of groups
We may also be interested in a succession of phases. This is actually the case of the succession of IUP, Ahmarian, UP and EPI that are in stratigraphic order. Hence, we can estimate the transition interval and, if it exists, the gap between these successive phases.
Transistions between successive groups
The transition interval between two successive phases is the shortest interval that covers the end of the oldest group of dates and the start of the youngest group of dates. The start and the end are estimated by the minimum and the maximum of the dates included in the group of dates. It gives an idea of the transition period between two successive group of dates. From a computational point of view this is equivalent to the time range calculated between the end of the oldest group of dates and the start of the youngest group of dates.
trans <- transition(chrono_groups, level = 0.95)
as.data.frame(trans)
#> label start end duration
#> 1 UP-EPI -31479.79 -26905.04 4574.757
#> 2 Ahmarian-EPI -39138.82 -27122.05 12016.769
#> 3 IUP-EPI -43487.53 -26866.99 16620.539
#> 4 Ahmarian-UP -39118.07 -36741.08 2376.985
#> 5 IUP-UP -43395.89 -36480.26 6915.633
#> 6 IUP-Ahmarian -43212.31 -40733.77 2478.539Gap between successive groups
Successive phases may also be separated in time. Indeed there may exist a gap between them. This testing procedure check whether a gap exists between two successive groups of dates with fixed probability. If a gap exists, it is an interval that covers the end of one group of dates and the start of the successive one with fixed posterior probability.
hia <- hiatus(chrono_groups, level = 0.95)
as.data.frame(hia)
#> label start end duration
#> 1 UP-EPI -29188.56 -28961.79 226.7663
#> 2 Ahmarian-EPI -37368.33 -28884.37 8483.9637
#> 3 IUP-EPI -41220.64 -28814.70 12405.9352
#> 4 IUP-UP -41282.64 -38421.49 2861.1474At a confidence level of 95%, there is no gap between the succession of phases IUP, Ahmarian and UP, but there exists one of 203 years between phase UP and phase EPI.
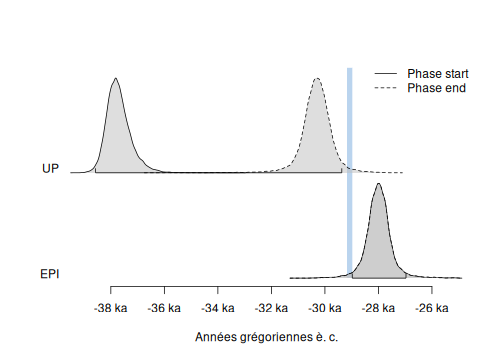
plot of chunk succession-plot